连绵阴雨今退散,
和风暖阳冬日暄。
浦江涟漪清波静,
门庭若市车马喧。
回首金牛辞旧岁,
虎虎生威迎新年。
玉盏流光庆欢聚,
恭祝幸福人康安!
— 恭祝大家新春快乐,万事顺意,心想事成,阖家康安!



连绵阴雨今退散,
和风暖阳冬日暄。
浦江涟漪清波静,
门庭若市车马喧。
回首金牛辞旧岁,
虎虎生威迎新年。
玉盏流光庆欢聚,
恭祝幸福人康安!
— 恭祝大家新春快乐,万事顺意,心想事成,阖家康安!
一直在使用VS Code来编写和运行Julia程序。
可是,自从VS Code的Julia扩展(Extension)升级到1.4.0版后,直到目前最新的1.5.6版本,都无法启动Julia。错误提示“julia.executablePath”设置不正确,需要重新设置(如下图)。就是说,指向julia.exe的路径设定不正确。

但实际上,julia.exe的路径设定是正确的。想到会不会是路径格式问题。于是试着将“\”改为“\\”或“/”,或是在路径外增加引号,但都无法解决问题。
到论坛、GitHub上寻求帮助,也没有答案。有朋友建议将Julia扩展降低版本使用。这倒是可以暂时解决,将Julia扩展降级到1.3.34版后,Julia可以在VS Code中启用。
本来以为这个问题能随着Julia扩展的进一步升级得到解决,可直到最近的1.5.6版,也还是存在同样的问题。作为“强迫症”患者,自己实在觉得这个不太容易忍受,于是再次寻找问题所在及解决方案。
先是尝试看GitHub上VS Code Julia扩展相关的源码,想找出些端倪,不过并未找到问题所在。
又尝试着在VS Code安装目录下,看看是否有Julia扩展相关的配置文件,想是不是可以直接修改相关配置文件,使julia.exe的路径设定可以起作用。也没有成功找到这个相关的配置文件。
突然一转念,想到既然是1.3.34版本可以正常使用,1.4.0版开始出现的问题,那看看1.4.0版和1.3.34版之间的差异,会不会能够找到问题呢?
在VS Code Julia扩展的文档主页(https://www.julia-vscode.org/docs/stable/)下的“Change Log”查找,发现了一点儿线索,与executablePath有关(如下图)。

顺着#2379这个链接,看到了关于这个更改的相关讨论及内容,是对“package.json”文件中的内容进行了更改。
于是,查找文件“package.json”,它是位于当前用户目录下的。以1.5.6版Julia扩展为例,具体位置是“C:\Users\当前用户名\.vscode\extensions\julialang.language-julia-1.5.6\package.json”。
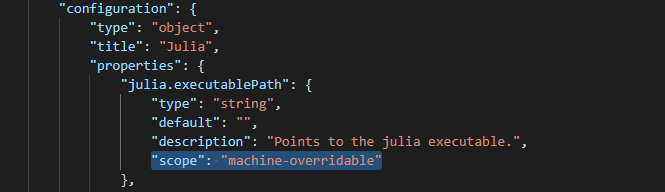
打开“package.json”(如下图),参照此前所看到的内容更改,将”configuration”–>”julia.executablePath”–>”scope”的原值”machine-overridable”改为”machine”,即改回为1.3.34版本中的值。
重新启动VS Code,Julia可以运行,路径错误的问题总算得以解决了。
没有深究”configuration”–>”julia.executablePath”–>”scope”的对应值具体含义,所以暂时还不清楚问题的根本原因,只是将问题解决了而已。
另外,这个路径错误问题,我只在Windows中遇到,在Mac中从未出现。也暂时没有深究原因。也许什么时候有空,再去研究一下。
此前,在Python中利用folium包,实现了一个交互式地图,在地图特定地点进行标记,并可显示该地点箱量。
自从使用了Julia后,希望能将这个生成交互式地图的功能通过Julia实现。看了Julia支持的OpenStreetMap,发现和自己想要的功能不太一样。Julia中的OpenStreenMapX包,是基于OpenStreetMap的地图数据文件进行操作的,需要下载OpenStreetMap的地图数据文件。
同时,也看到了,Julia可以通过PyCall包,使用folium来实现生成地图的功能。但是,自己还是希望能够使用“纯粹”的Julia,而不是调用Python的功能包来实现。
查看了很久,发现似乎没有别的更好的选择,只好尝试通过PyCall包,引入folium来生成地图。
使用PyCall,要注意设定Python环境,使用 ENV[“PYTHON”]=”Python路径” 这样的设定,自定义Julia将要调用的Python。环境设置后,PyCall包要重新build一下才可以使用。
在Julia中调用Python还是比较方便的。
以使用folium为例,程序起始要有“using PyCall”,以便调用Python。程序中,使用类似 folium = pyimport(“folium”) 的语句,生成名为folium的PyObject。这个folium与Python中“import folium”后类似,可以使用如 folium.Map() 这样的形式调用folium包中的函数。
但在使用中,要注意一些Julia与Python语法不同的细节。我为了方便,将原先Python的代码copy了过来,但有些地方就会报错。比如Python中,两个字符串可以用“+”连接,但到了Julia,就要把“+”改为“*”。还比如,Python中使用“True”,而Julia中对应的是“true”。还有类似数组下标起始不同,根据数值范围循环,数值区间不同等等。
将这些改好后,运行代码,与使用Python时一样的交互式地图就生成了。
Python前阵儿发布了3.10正式版,没有多想,和以往一样,将自己所用的Python也随之升级到了3.10版。
不曾想,升级后,使用中却出现了一些问题。
首先,有些包不支持Python 3.10,甚至包括很基础、应用很广泛的如NumPy、Pandas、SciPy等。尤其是Numpy,许多其它的包都依赖NumPy。NumPy无法正常使用,导致依赖它的包也不能正常使用。
到GitHub上看了一下,貌似也没有什么好办法,因为急用,只好将Python回滚到3.97,临时凑合一下。
然后就常常看NumPy的消息,终于盼到NumPy推出支持Python 3.10的版本,立刻安装了。本以为这样可以解决问题,可是发现,Pandas仍然不能正常安装。因为Pandas的当前最新版本依赖的不是NumPy的刚刚推出的最新版本,而是NumPy此前的版本。所以,虽然NumPy已安装完毕,Pandas还是不能安装。
这样,需要使用Pandas的程序,还是不能正常运行。老样子,到GitHub上去看,貌似也没有直接的解决方案,好像说要等待Pandas推出支持Python 3.10的版本。不过,找来找去,似乎看到Pandas成员有人说Pandas目前可以使用在Python 3.10环境中,但针对Python 3.10的版本wheel还没有生成。看到这里,心里有了一点儿希望,就想到,不使用pip进行安装,而是下载源码后,尝试直接本地编译安装的方法(需要Cython包)。于是将Pandas的最新版源码文件 pandas-1.3.4.tar.gz 下载,然后使用“python setup.py install”来进行安装。不错,Pandas竟然安装成功,可以使用了。这下,困扰多日的问题,总算暂时得以解决。
本想照葫芦画瓢,把SciPy也这样安装上去,可惜失败了,没有仔细研究问题所在。有空时慢慢研究或等待支持Python 3.10的SciPy版本吧。
还遇到一个问题,是Python 3.10中,标准包collections升级改动引起的。
在Python 3.10中,“from collections import”这样的语句已经被弃用,应当改成“from _collections_abc import”。
发现这个问题是使用pyecharts包时,包目录下render\engine.py源文件中,有一行语句“from collections import Iterable”无法正常运行,提示import失败。查看了新版collections的文档和__init__.py源文件,发现了上面提到的语句弃用问题,于是将engine.py源文件中的语句改为“from _collections_abc import Iterable”,这样,pyecharts包就可以正常使用了。
Python这次升级,改动较大,甚至支持了类似switch…case…的语法,给大家带来更多方便。不过许多功能包还没有对Python 3.10提供及时支持,可能全面方便地应用,还要再过一段时日。
最后,说一个和此次Python升级无关的问题。
使用pivottablejs包来读入Excel文件,生成数据透视表时,发现总是会有莫名其妙的空值,空值个数与读入的Excel表行数相同。后来得知,这是因为不同的换行符格式导致的。在pivottablejs目录下__init__.py文件的pivot_ui()中,增加” newline=’\n’ “作为io.open()的最后一个参数,空值的问题就解决了。
使用Julia的Plots包,加上Plotly(JS)做后端,可以方便地绘制出各类漂亮的图表。
前一阵儿,使用Plots包中的plot函数,绘制柱形图(类型参数设置为柱形图,seriestype = :bar)时,还会出错,提示参数不符。现在,又试了一下,发现已经可以使用,直接用plot函数就可以绘制柱形图。
因为需要绘制堆积柱形图,于是就查看Plots的文档,看应该如何设置参数,绘制柱形图。
看起来很简单,只要在plot函数中,将参数“bar_position”设置为“:stack”即可。但文档中还有一句提示,告知堆积参数可能无法完全生效。而柱形图默认的是叠加覆盖(overlay)模式。
尽管如此,还是尝试了一下,果然堆积参数无效,无法绘制出堆积柱形图,仍然是叠加覆盖模式。
于是寻求解决方案。
在Julia中文论坛和国外论坛、GitHub的Plots板块都进行了搜索,发现这的确是一个问题,而且目前似乎也没有解决。看到有网友建议使用StatsPlots包中的groupedbar函数,来实现堆积柱形图的绘制。
但尝试了一下,发现groupedbar所用参数与plot函数不尽相同,而StatsPlots文档中groupdebar的说明也非常“简陋”,只是举了个例子而已。
只好自己根据groupedbar函数的例子进行研究,发现plot函数,使用的数据,参数类型可以是Array(数组,一维或多维均可);而groupedbar函数,对应的数据参数,必须是Matrix(矩阵,即二维数组)类型。因为在这段程序中,要绘制多个图,并将多个图整合在一页;所以就想尽量省事,少使用些函数和变量,不要过于麻烦,仍然想统一用plot函数解决。
到Julia中文论坛,专门提问这个问题,有热心网友 Jun 告知,plot函数一直不支持堆积柱形图,只能用StatsPlots包来解决。
于是,只好改写原来的程序。使用StatsPlots包的gropuedbar函数,并将传入的数据类型改为Matrix,参数“bar_position”设置为“:stack”。其余参数如数据标签、图例等,都和plot函数类似,无需改动。
这样,总算是成功绘制了堆积柱形图,并最后将多个图表进行整合。
前一阵儿大热的连续剧《觉醒年代》,广受好评。不太追剧的我,也被其深深吸引触动……
《觉醒年代》反映建党前的一系列历史事件和进程,而当我们了解历史后,更加会觉得,“中国共产党是历史的选择”,这绝不是简单的口号和臆断,而是真真确确的事实。
自清末开始,由于国力羸弱,屡受外辱,多少仁人志士探索强国之路。但是,在党成立前,却没有一条路是行得通的。无论是君主立宪、民主共和,抑或无政府主义,无一不在现实前碰撞得“头破血流”;没有一个能切实地改变中国,使中国走上富强之路。
“十月革命”一声炮响,为中国带来了另外一种可能;而作为“学生”的中国共产党,却没有死搬硬套其模式,而是根据中国国情,辩证、历史地看待和处理问题,走出了一条独特的、适合自己的道路。
“全心全意为人民服务”,为最广大的人民群众谋取利益,这是党的初心,也是中国共产党与其它党派最大的不同。同时,这也是党拥有广泛群众基础,从成立至今,一个世纪来,能克服各种艰难险阻,不断走向胜利的原因。
想到《觉醒年代》剧中,陈独秀、李大钊两位先生,在海河岸边,见到百姓流离失所,不禁痛哭流涕,并立下誓言,为解救中国劳苦大众而奋斗。这是剧中,少有的李大钊先生痛哭悲伤的情节。就我个人感觉而言,李大钊先生几乎就是最具有代表性的中国共产党一员。他的奋进、激昂,与群众结合,乐观向上,无不是共产党员的典型特性。陈独秀先生有时也会“迷茫”,而李大钊先生自从认定了马克思主义理念和社会主义道路,就一直乐观坚定地向前看。李大钊先生那种乐观主义精神,我觉得也是我党能在各种恶劣环境下,面对困难、强敌,却仍然顽强斗争、勇往直前的精神动力。
回首当年,谁也不敢想象,成立时如此“简陋”的中国共产党,竟然带领中国人民,击败外敌,解决内患,推翻了一座又一座大山;自力更生、艰苦奋斗,傲立于世界东方;并继续带领人民,走向富足光明的未来。
前进的道路总归不是一帆风顺的,但党的一个特点是强大的自我纠错能力。正是这种自我纠错的能力,使得我党在前进过程中,能够及时纠偏,继续行进在正确的道路上。
曾几何时,一些不和谐的声音开始出现,试图扰乱人们的视听。这些声音或是编造所谓“史料”,歪曲事实;或是采取历史虚无主义,妄图抹杀史实;或是假装“理中客”,暗中带节奏,误导大众;或是做杠精,无论什么角度,都要进行辩驳。
这些事例不胜枚举,从所谓我党抗日,游而不击,到主席《论持久战》并非原创;从声称民国政府比我党更注重教育,到编造毛岸英烈士牺牲过程;从分析邱少云烈士事迹不符合生理常识,到为731部队洗白;从贬低袁隆平爷爷,到夸大我们与他人差距。
其实稍微查查真实史料,稍微客观、逻辑地分析一下,就知道上面那些谬论有多可笑,多不堪一击。
我党领导的敌后抗日根据地,牵制了日军的大半兵力,而八路军、新四军及敌后抗日根据地武装,在对日作战次数上,也超过了国军。诚然,国军有英勇抗日的将领和士兵,但以蒋委员长为首的国府,从来就没有把自主抗日当作第一选项。国府总是寄希望于“外援”,却总是忘记了最主要的是“自强”。
说到抗日,连日军的一些作战记录年鉴,都明确记录说明了共产党领导的军队,战力及牺牲超过国军。但这样的史料,许多人视而不见,却对不知从何而来的“路边社”消息奉为至宝。
所谓民国政府重视比我党更重视教育,这也是无稽之谈。民国时期,固然有大学、有大师,但仍然是为最顶层的“精英”服务的,绝大多数普罗大众仍然是没有受教育的机会。而我党的理念是,为最广大的人民群众谋福利,全面提高国民素质。正是这样,我国的文盲率才迅速降低,才有了当今的九年义务教育。
如果将那些谬论一一驳斥,恐怕要花费大量口舌,而且也永远无法叫醒那些装睡的人——他们并不真的在乎“六子吃了几碗粉”,他们的目的就是要污蔑甚至让六子死。
所幸,近年来,这样的言论越来越没有市场,越来越被广大人民所鄙视。大家也越来越看清,中国共产党,才是真心为了百姓利益奋斗和奉献的群体。
而中国共产党,也必将牢记初心,不忘使命,带领全国人民,迈向下一个新时代。
这几天,工作中需要整理大量文档,而且,需要将文档中特定部分摘录汇总。可是这些文档均为扫描而成的pdf文件,如果将其中需要的特定部分进行摘录,需要重新打字转录,那真是费时费力。可工作还要进行,这可如何是好?难道只能硬着头皮一个一个打字?那真是不符合我们“懒人”的做派。
突然想到Julia中可以使用Tesseract包实现OCR功能,于是就试试这个方案。
将文档中需要摘录的部分截屏存为图片,准备使用Julia来进行OCR。这里需要Images包和Tesseract包(using Images和using Tesseract)。
因为是英文文档,所以使用 download_languages(“eng”) 来初始化Tesseract进行OCR的语言。此前曾出现过无法正常下载语言文件,导致Tesseract不能正常运行的情况。如果遇到这个问题,可以直接下载语言文件,并放置入Tesseract相应文件夹中即可。
操作其实比较简单,先是TessInst(“eng”)初始化一个基于英语的实例,再使用 pix_read() 读取打开的图片文件。然后用 tess_image() 将读取的图片文件信息导入实例,最后将实例作为参数,使用 tess_text() ,即可获得OCR的文字了。
可是,不知什么原因,无论是用VS Code还是Jupyter Lab,执行 tess_text() 时总是报错或假死机。根据VS Code提供的错误代码,到其主页查看,似乎是兼容性的什么问题。
后来,不使用IDE环境,直接启动Julia,将代码copy至Julia REPL中,可以正常运行并得到结果了。
在代码后段,使用文件操作函数——open(),write()和close(),将OCR结果保存至文件中以备后续使用。而且,为了方便及提高效率,使用Gtk包,反复打开需要OCR的图片文件,将多个结果保存在一个文件中;并在保存每个图片的OCR结果时,将图片文件名添加进去,进行对应,方便此后查询。
这样,不多时,一批文档的特定内容就全部读取完毕,只需核对OCR结果与原文档内容是否匹配,并汇总即可。
对于有娃的家长来说,鸡娃or不鸡,that is the question…… 尤其当下,恐怕更多的不是“鸡”或“不鸡”,而是怎么“鸡”的问题了。
我们对番茄的态度,不是随意放任自流,但也不希望做拼命三郎,算是尽量找个平衡吧。
说起《千字文》,源于最初考虑用什么方式教番茄认字,试过文字卡片、看图识字等,但我个人觉得必须要有个“目标”,而且还要坚持。卡片类的东西,很容易淹没在番茄的各种玩物和书中,后来突然想到了《千字文》。
老祖宗的许多遗产,真是不错。《千字文》,是由一千个汉字组成的韵文,四字一句,行文工整,条理清晰。而且原文本是一千个不同的汉字,虽然现在使用的是简体字,有些重复,但绝大多数仍是不同的字。于是想尝试以此为目标,带番茄一起读并试试教她认字。
可能许多人觉得《千字文》太难,不适合小朋友学字;也有人觉得字数太多,开始没有必要把目标定的这么高;还有人认为,小朋友学习要培养兴趣为主,不能是辛苦学习,这样效果不好。
我个人觉得,现在小朋友学习的许多方向,被带歪了。
首先说学习的辛苦。诚然,兴趣作为学习敲门砖,的确对引领小朋友学习有很重要的作用。但学习,尤其是比较深入的学习,永远都不是轻而易举之事,即使有强烈的兴趣,也是要付诸辛苦的努力——这个是我一直以来的观点——绝不能指望依靠兴趣,可以轻松学习,这是自欺欺人,也是绝不可能实现的。现在的小朋友接受事物的广度、深度,远超当年同龄时的我们,所以,在合适的时候,应该让小朋友正视学习的辛苦,而不是逃避,不能用兴趣、轻松、或“利诱”这些概念方式来贯穿小朋友的学习过程(虽然许多时候,适当的“利诱”在所难免)。应当让小朋友知道,学习是必要的而且是辛苦且要付出努力的。
许多人说,如果让小朋友知道学习辛苦,需要努力,小朋友就不愿意学了。这话有一定道理,惰性是人的天性之一,谁都希望舒舒服服躺在“舒适区”。但真躺平在舒适区,就意味着没有前进,真正的前进是不可能轻松的。说到小朋友是不是不愿意付出辛苦去学习,我觉得从天性来说,的确很难心甘情愿自己“受苦”,但家长的一个重要任务,就是陪同孩子走过这段路程,让孩子能够接受学习的辛苦。可能方法有很多,我觉得最重要的是能以身作则,要“陪同”小朋友一起“辛苦”学习,而不是把学习变成小朋友自己的任务,而家长只做抽打小朋友前进的“鞭子”。
除了“快乐”学习这个“歪理邪说”之外,还有一种观点,我觉得也跑偏了。就是过分强调不能死记硬背。其实,小朋友的机械记忆力超过理解记忆力,而且记忆力是需要锻炼和培养的,如果一直不用,那么必然会有所谓“什么也记不住”的现象。所以,记忆,在学习的过程中是必不可少的。哪怕是数学这样的科目,熟练应用的基础也是能够理解并牢记各类公式及概念。所以,“识(zhì)记”很久以来就是作为学习的一个重要步骤,甚至可以说学习是由识记开始的。
我个人认为,一个人学习的能力或知识的范围,就像是一个蓄水池。在年纪小的时候,由于理解能力等方面的限制,可能无法深挖,但广度却是可以扩充的。如果广度很大,随年龄增长再挖深度,那么学习能力和知识范围将会相当可观。如果小时候没有扩充广度,到需要挖掘深度的时候,如果想同时再扩充广度,那么所需要的努力,将会更多。
而且,我们认为困难的事情,也许小朋友并不认为那么困难。比如说我,小时候无聊,自己去背圆周率,最多时能记下来三百多位,现在也能记住一百四、五十位。如果现在才开始让我去背圆周率,肯定觉得很困难,但小时候无聊,随便记记,也就把它给记住了,并且多年不忘。
大家都认为现在的小朋友比我们小时候有见识,那就别小看他们,相信他们的能力。好比说我们以前一直认为小朋友三岁前不记事儿,发生了什么,自己完全没有记忆。可是番茄二十个月到巴黎,三岁不到去巴塞罗那,这两次经历,她虽然不能记住全部细节,但自己头脑中还是有很多“存货”的,偶尔自己还会说起。
所以,我们应当重新审视小朋友们的能力,不要用我们自己的局限来给小朋友们设限。当然,我不是说要揠苗助长,只是说,不要过于“轻视”小朋友而忽视了他们的真正实力。
另外,再说两个我觉得正确的但许多人不认同的“歪理邪说”:
正确的“歪理邪说之一”——人的记忆肯定是受限的,但大多数时候,是按比例丢失的。就是说你能记住的(指短期记忆),是你试图记住内容的百分之七十左右。那么你如果尝试记住十个单词,可能最后就只记住了七个,但如果你试图记住一百个单词,最后可能就记住了七十个。这里不做准确定量分析,只说大概。基于这个理论,需要背的东西,尽量多背,而不是画重点。比如我们中学时期的历史、地理、包括生物等大量需要背下来应付考试的内容,如果只背老师画的重点部分,最后记住的就是重点部分的百分之七十左右,如果尝试把所有知识点都背下来呢,那记住的就是全部知识点的百分之七十左右。以全部知识点的百分之七十去应对以老师重点部分为主的考试内容,绝大多数情况下,是绰绰有余。更何况,多背两次,记住的就不止百分之七十了。
正确的“歪理邪说之二”——理科,尤其数学,可以“降维打击”。许多人都强调,小朋友的数学题难,不仅本身难,往往还难在不能使用超纲的知识。是的,解题不能用超纲的知识,但没说你思考不能用超纲的知识啊。如果使用微积分,是不是许多极限方面的问题都迎刃而解?如果设立方程,是不是许多算术应用题都可以迎刃而解?这个难点在于,高维的知识是否能够理解或掌握,如果真的理解或掌握了,“降维打击”低维度的问题,是非常容易的。而且,当思路清楚后,也可以很容易转化为用同维度的知识来解决。使用高维知识,经常可以迅速地找到思路,解决问题。所以,不要再拘泥于所谓不能使用超纲的知识,知识是拿来灵活运用的,而不是自我设限的。
回到《千字文》,经过这么长时间,磕磕绊绊,小番茄总算是把《千字文》一课一课坚持全部读下来了,虽然不知究竟真正认识其中多少字,但总应该聊胜于无吧。
而且,通过这个过程,也让她知道了几件事情:
一、学习是辛苦且需要付诸努力的;
二、虽然有些事情不愿意或不容易,但还是必须要去完成的;
三、学习获得的成果或成绩,还是很有自豪感和成就感的。
当然,在小番茄读《千字文》的过程中,我们也没有完全照搬我们小时候的方法。比如没有特别强力的逼迫;在开始的阶段,还是引导并激发她自己的兴趣,尤其是她的“虚荣心”,让她觉得自己认识很多字,那是很“赞”、很“牛”的一件事情。所以她开始还是愿意跟着读,但后来,越来越艰难,她也会“耍赖皮”,想逃避。如上文提及,对于这个问题,我们此时没有去回避或糊弄她,而是坦率告诉番茄,学习的确有些累,但这并不难,她只要坚持,完全可以克服;同时,也告诉她,有许多事情,是必须要去完成的,不能随意任性;还有很重要的是,随着她读的进程,不断鼓励她,强调她的进步,尽量激发她的自豪感(我觉得这是我们小时候,父母师长对我们的教育过程中,相对来说比较欠缺的)。番茄慢慢也接受这个事实,虽然觉得累,但还是慢慢坚持下来了。
娃学习的过程,其实对父母来说,也是一个学习的过程。希望我们都能陪伴自己的孩子,走向美好的明天。
又是很久没有去过杭州了,有多久呢?——— 对于喜爱杭州的人来说,从离开杭州的那一刻开始,就已经很久了。
清明时分,气温宜人,全家驱车前往杭州一游。晚餐后启程,抵达杭州,已近夜半。
翌日上午,出得住处,片刻即行至西湖。沿湖边向断桥方向行进,湖水清清,垂柳依依,游人众众,共享春意。


自上次西湖游船后,番茄即喜爱上了西湖泛舟,来杭前就满心惦记。我们过断桥、行白堤、经平湖秋月,浙博一旁,恰有船泊,遂登船而行。
艄公边摇橹行船,边向我们介绍西湖风光、传奇轶事;至小瀛洲、三潭印月,方才返回。


水波微澜,扁舟轻荡,远眺山色,近赏湖光,徜徉其间,几欲不返,虽无醴醪,景迷人醉 ——— 正所谓“醉翁之意不在酒,在乎山水之间也”。
船靠岸后,稍事歇息,返回酒店,番茄累得趴在我肩上就睡着了,回酒店后,直睡到快吃晚饭,才醒过来。
又一日,吃过早饭,我们和番茄一起去看“老朋友” —— 上次在湖边看到的小松鼠。“老朋友”果然在等我们,应该是等我们给它好吃的。看它双手抱着玉米,埋头认真啃的样子,真是憨态可掬。

看过小松鼠,我们先沿湖边而行,后至河坊街,过鼓楼,顺便参观了胡雪岩旧居 ——— 虽然来杭州这么多次,但此前从未到胡雪岩旧居游览过,这次也算“查缺补漏”了。




我们在中山南路的菊英面店吃晚饭 ——— 以前就在《舌尖上的中国》看到过菊英面店的介绍 ——— 超级爱干净,有洁癖的老板,随性放暑假的经营 ——— 不过却一直没找到机会来吃,这次碰巧,满足了心愿。虽然据说现在菊英面店引入了外部资金,老板也成了“打工人”,但面的味道还是相当不错的。
面店的路对面有个小摊位,卖叫花鸡和酒酿。虽然只是个小摊位,恐怕连店都算不上,桌椅就摆在人行道边,但叫花鸡和酒酿的味道都很好。泥土包着的仔鸡,骨酥肉烂;一钵钵的酒酿,清凉甜香。
第三日,想去龙井,但又觉交通不便,且当日还需返沪,颇有些纠结。恰好酒店大堂茶室,可以提供龙井往来游玩的服务,于是请其帮忙安排。
至龙井村,我们兴致勃勃地沿小路爬茶山,尤其是番茄,开心地化身“采茶女”,一直上到“最高处”才尽兴而返。蓝天、白云、绿树,伴着幽幽茶香,令人心旷神怡。

下山后,于茶室小坐,品明前龙井,学采茶、炒茶,轻松惬意。
愉快的清明假期杭州游结束了,期待下次再来与杭州相聚。
近期,要做一个相对来说有些麻烦的数据分析,需要综合Excel多张表中数据,根据特定规则进行综合分析计算,以得到所要结果。
分析数据,首先是读取文件,文件中有几张表,总共大概三十万条数据。其中一张表中的数据是后期数据统计分析的基础。该表中七万多条数据,要以某列String型字段为关键字,首先选出基础数据集合,就是这些数据中,对关键字的重复进行筛除,以不重复的这些关键字所组成的集合作为后续分析的基础。
使用Gtk和XLSX来选取和读取文件,然后设置了一个元素类型为String的空集合,并开始遍历Excel表中数据,逐条读取后,形成集合。
看起来逻辑没有问题,谁知程序运行时却出现“假死”状态,后来耐着性子等,并用@Time看了一下,才发现,遍历七万多条数据读取,去除掉重复数据(这是Julia语言运行集合运算时,自动执行的),形成六万多元素的集合,竟然花费了差不多5000秒的时间——这也太夸张了。以为集合运算要判断元素重复的情况,所以花费时间(其实自己也知道应该不会是这个问题,如果这样,那更大的数据量怎么办?),就尝试了一下生成列表,不进行元素重复的判断,结果用时几乎没有区别。
自己想不出所以然,就去Julia中文社区QQ群里请教大家,马上就有热心网友回复了,推测是因为Excel数据逐条读取效率低下引起的,建议读入形成DataFrame,再进行数据操作。
按照网友指点,使用DataFrame形式(可以用XLSX.gettable函数读取Excel整表内容再生成DataFrame),从DataFrame中逐条读取数据,生成集合,果然“瞬间”就完成了。
这下明白了,今后读取Excel文件数据,尤其大量数据,要整体读入,使用DataFrame形式,再对数据进行操作。
数据整理完毕,还对一些时间类型数据向数值进行了转换(使用Dates.value函数),然后准备将其可视化成柱形图(bar chart)。使用Plots相应功能,可以方便绘制柱形图,但不够美观。于是使用Plotly作为后端——此前常用Plotly作为后端绘制折线图,生成的图形非常简洁漂亮,所以我比较喜欢用Plotly做后端。
可是,随着Plotly后端运行,却无法使用Plots绘制柱形图,无论是使用Plots.plot函数中的参数设置seriestype=:bar,还是使用Plots.bar函数,都不能正常运行,提示参数不符或函数不对。
反复思量无果,就准备试着直接调用Plotly中的bar函数来绘制柱形图。查看了Plotly相关文档,然后使用bar函数,终于成功绘制了柱形图。
不过,也许我文档看得不够仔细完整,Plotly下的bar函数,绘制柱形图感觉不如Plots.plot函数使用方便、灵活。根据Plots文档来看,其实Plots.plot函数功能强大,绘制图形相当灵活,参数设置也很方便。可惜在Plotly做后端的情况下,有许多限制,参数seriestype设置对很多类型无效,柱形图即是其中一例。不知今后会不会有改进。
Julia作为比较新兴的语言,用户群体数量不够大,所以许多包和功能可能不够完善,距离Python的丰富生态还存在距离。但现在应该越来越多的人开始使用Julia了,希望将来生态会更加丰富,让我们使用也更加方便。
金牛已至又岁除,
云霞明灭焕黼黻。
喜换新桃千家户,
繁灯流华掩星疏。
和风轻暖花锦簇,
金樽玉盏屠苏入。
欢声笑语凝丝竹,
幸福康安与君祝。
——恭祝大家新春快乐,万事如意,阖家团圆,幸福康安!
话说这段儿时间,忙上课、忙作业、忙文献、忙工作,竟然还有空看“没用”的书,做“没用”的事儿?不过,前人有云,“不行无聊之事,何以遣有涯之生?”做些“没用”的事儿,权且当作生活的消遣调剂。
谈到古典小说,我个人觉得,恐怕《红楼梦》(此处及以下均指前八十回,不包括后四十回高鹗的狗尾续貂)稳居鳌头,无出其右者。
曹雪芹的神来之笔,无论细节勾绘或是结构框架,无论市井鄙俗或是朝堂高雅,无论诗词联楹或是行文刻画;黛玉之灵秀,宝钗之端庄,凤姐之泼辣,湘云之活泼;都描摹得入木三分。但这大部头的巨著,的确也不容易读,非要静心沉浸其中,否则难得其妙;而一旦得窥堂奥,恐怕就不是读一遍、两遍能放下的了。
前阵儿读完了刘心武先生的全套五册《刘心武妙品红楼梦》。回想自己看过几位大师关于《红楼梦》的著述评说,真是风格各异,趣味迥然。
这几位大师中,最具权威的,自然是周汝昌老先生。《周汝昌校订批点本石头记》、《红楼小讲》、《红楼新境》都曾拜读,但老先生成名作《红楼梦新证》,尚未读完。
周汝昌老先生,毕生钻研红学,尤其是考证,更是他对《红楼梦》研究的一大特色。周老先生对《红楼梦》背景、文字、脂砚斋的评论均进行了详尽的分析和考证,建立了自己的理论体系,同时,也据此对《红楼梦》的各个版本及内中文字提出了自己的看法。
就个人而言,大概因为先入为主,相对来说,最接受周汝昌老先生的观点。周老先生的两本小书《红楼小讲》、《红楼新境》,篇幅不大,但都很有趣儿。
不过,大概老先生太过于注重小说文本与考证的关系,所以有些地方似乎稍微过头了一点儿,《周汝昌校订批点本石头记》中,因为考证所得结论,老先生对文本删改幅度有些过大。但整体来说,周老先生的考证、分析我个人觉得非常令人信服。而且,有了这样的考证分析,可能对曹雪芹“草蛇灰线,伏脉千里”会有更多的理解,再看脂砚斋的评论也更能会心一笑或心有戚戚。
跑个题,如果说我看过的《红楼梦》文本最好的版本,恐怕是浙江出版集团数字传媒有限公司出版的《红楼梦脂评汇校本-繁体竖排版》。这是只可使用Kindle(或其软件)来读的电子版本。但这个版本应该是比较了很多不同版本的优劣,进行了综合考量后所得。而且繁体竖版,读起来尤有古意。
对《红楼梦》的评说中,蒋勋老师的《蒋勋说红楼梦》我也非常喜欢。很早就读过他的《孤独六讲》、《写给大家的西洋美术史》等书籍,很喜欢他的风格,也就成了他的“粉丝”。《蒋勋说红楼梦》最早出版的时候,八辑我是像追剧一样,出一辑,追一辑,直到读完。
蒋勋老师作为美学大师,对《红楼梦》的评说有另一个独特的角度,不作考据,只看文字,只对文字本身进行介绍和解读。蒋勋老师的解读淡泊“佛系”,从入世修行的角度,对红楼人物进行了解读。文如其人,温文尔雅,娓娓道来,读之心定神宁,对《红楼梦》另有一番感悟。但与后文将要提到的白先勇先生不同,蒋勋老师虽然不作考据,但并不反对考据。
刘心武先生对《红楼梦》的解读,如其所言,并不是“推销”自己的观点,而更多是希望引起大家对这部巨著的兴趣。刘心武先生在总体框架上,也是认同周汝昌老先生观点的,所以,刘心武先生还据此续写了《红楼梦》(续文共二十八回),以纠正高鹗所续后四十回的谬误。不过,由于时代、文笔习惯不同,刘心武先生所续之作,在大方向上也许是秉承了曹雪芹的原意,但行文的确不是很耐看,可读性不如《刘心武妙品红楼梦》。但无论怎样,如刘心武先生所言,引起大家对《红楼梦》的兴趣和关注,这就足够了。
不知何时,《白先勇细说红楼梦》好像红火了起来。看到网评夸赞之声不绝于耳,我便不能免俗地买书来看。
可惜,白先勇先生的作品于我个人感觉而言,并无十分精妙之处,甚或有“错误”存在。
白先勇先生认为“考证”无用,认为曹雪芹不会埋下如此多的伏笔,让读者来“猜”。但如前所言,我比较认同周汝昌老先生的总体观点,所以,觉得白先生的看法并无坚实依据。另外,借用刘心武先生的说法,《尤利西斯》之中,有大量的隐喻暗指,为什么没有人怀疑这些隐喻暗指的存在,却不能接受《红楼梦》中的隐晦所指呢?而且,脂砚斋也多次提到“草蛇灰线,伏脉千里”,旁证了曹雪芹的脉络设计。这其实并非是让大家猜,而是巧妙的构思。
脂砚斋,如果没有她的评点,会少却很多乐趣。读《红楼梦》,同时看脂砚斋的评点,往往会产生与古人心意相通之感。
脂砚斋,无论从其名,或是其评点,均可看出是女儿身(她与畸笏叟是否为同一人,尚存争议)。尽管曹雪芹后来贫困潦倒,但著书之时,若有脂砚斋这样的聪慧女子红袖添香,也能勉强宽慰我等对曹雪芹的悲怜叹息之心,符合对古人的幻想遥思。脂砚斋评点中,也曾回忆起与曹雪芹共渡的“浪漫”往事。
但白先生却认为脂砚斋是曹雪芹的伯父或类似人物,这应该是将对畸笏叟的一些人设和观点强加到了脂砚斋头上。试想,一个糟老头子,在评点而不是虚构作品中,发灵秀女儿之声,甚或回忆起与曹雪芹的“浪漫”往事,这是多么恐怖的一件事情?所以,脂砚斋如何会是曹雪芹的伯父,必定是红颜知己才对!
还有一个“低级”错误,更是不应该出现在白先生的评述当中了。白先生在谈及第五十三回,贾府祭宗祠,宝玉捧香,贾菖贾菱展拜毯时,竟然说贾菖贾菱是跟宝玉同辈的亲戚。
这个错误实在太不应该了。无需通读《红楼梦》,只要对中国文化稍微了解便知,如贾府这样的大户人家,取名均有一定之规。比如贾珍、贾瑞、贾环,都是同辈,单字名,且名字为“玉”旁;宝玉不同,书中已说明原因,但其实也是“玉”。而贾蓉、贾蔷、贾兰(繁体作蘭),都是同辈(比宝玉低一辈),单字名,且名字为“草”头,贾菖贾菱也应当与他们同辈而不是与宝玉同辈。
如此明显而“低级”的错误,更使我对白先生的著述敬谢不敏了。虽然读完,但并无赞叹倾佩之感。
说到“红楼”,自己读过数遍,但也已好久未曾开卷。待得闲暇之时,可再拜读赏味。
前阵儿《定量方法与研究》的课程作业,是对给定的数据进行分析。尽管通常来说,应该使用SPSS操作,不过一来手头没有SPSS可用,二来也想找机会练习一下Julia,于是决定使用Julia作为工具进行数据分析。
大概Julia使用者还是远远不及Python,因此文档并不丰富,而且组织零散。尽管知道自己需要的数据分析功能,Julia及相关包(package)一定可以实现,但具体应该使用哪个包及包内功能却有些无所适从。
隐约记得Julia中与统计相关的包不少,而GLM包是和线性模型有关的。于是到 GitHub(https://github.com/)和 JuliaStats(https://juliastats.org/)搜寻。谁知,虽然看到GLM应该正是所需要的包,但GitHub中GLM包相关的部分却没有给出文档,在文档处无链接。记得以前在GitHub搜寻到Julia相关包的部分,往往都会给出文档可供参考的。
没找到GLM的“官方”文档说明,只好在 Julia Discourse Board(https://discourse.julialang.org/)看看能不能有别的发现。恰好见到有人在使用GLM包中的“lm”函数,好像是可以用来进行一元回归分析并构建模型。于是在Julia的REPL界面使用“@doc lm”查看了一下,果然适用。一定要注意,lm函数传入的用来进行分析的数据参数(第二个参数)必须是DataFrame类型。

这下,一元回归分析及模型可以构建出来了。接下来想对模型的拟合度进行一下检验,需要计算样本决定系数(coefficient of determination,R^2)。网络搜索了一下,介绍样本决定系数的很多,但一下子没有找到在Julia中如何进行计算。于是又到 Julia Discourse Board 搜寻,竟然如此简单,直接使用“r2” 这个函数检验此前回归分析所得到的模型,就可以计算样本决定系数的值了。“r2”这个函数也是在GLM包内的。
至此,数据的线性回归分析、模型的构建以及拟合度检验均告完成。
七十年前的10月19日,有许多人,为了正义、为了和平、为了人民的安居乐业、为了祖国的安宁稳定,穿着单薄的衣衫、依靠简陋的武器、吃炒面、喝雪水,与武器装备精良、后勤保障充裕、武装到牙齿的敌人,进行了一场艰苦卓绝的战斗。
这些人,在零下四十度的严寒中,爬冰卧雪;在震耳欲聋的炮声中,坚守阵地;在敌人疯狂的扫射中,英勇挺身;在熊熊燃烧的烈火中,百炼成钢。
他们,就是中国人民志愿军,为祖国和人民,英勇顽强、不畏牺牲,雄赳赳、气昂昂,奔赴战场,与敌作战。
著名作家魏巍,称他们为“最可爱的人”。“我在这里吃雪,正是为了我们祖国的人民不吃雪”,“可是我在这里蹲防空洞,祖国的人民就可以不蹲防空洞啊”,他们的话语朴实,却又闪烁着高尚的光芒。
 (鸭绿江大桥)
(鸭绿江大桥)
国庆期间,带番茄来到鸭绿江断桥。虽然我算是半个军迷,但番茄是女孩儿,而且年纪又小,我从来没有给她讲过战争或武器,她对此也毫无概念。站在断桥旁的高射炮上,她开心地学小猫叫。
 (站在高射炮上学小猫的番茄)
(站在高射炮上学小猫的番茄)
我想,正是无数先烈的流血牺牲,正是志愿军的保家卫国,才给我们这些后辈留下了宝贵的遗产,能让番茄一样的孩子们,无忧无虑生活在灿烂的阳光下,而无需担心战争的阴霾。虽然“忘战必危”,但能让百姓“忘却”战争、幸福生活,这岂不正是先辈们为之奋斗的目标吗?
伟大的中国人民志愿军,也创造了战争史上的奇迹,有许多人称之为“轻步兵”的巅峰。以如此简陋的装备,面对武器质、量,均远远超过自己的敌手,获得如此战绩,的确令人不可思议。也有人称抗美援朝,是唯一一次以精神力量,抹平了武器代差的战争。
 (抗美援朝纪念塔)
(抗美援朝纪念塔)
时光荏苒,七十年过去,虽然志愿军精神仍在——我相信我们的军魂永在——但现在我们的士兵不必再以单薄的衣衫面对严寒,保暖军服及装备已经普及;也不必再以雪水拌炒面充饥,现在不仅食品丰富,甚至可以无人机送餐;也无需再用简陋的武器面对敌人的强大火力,我们的火力配备已经罕有匹敌。据报道,某些步兵班即装备4具单兵多用途火箭筒和2具单兵云爆弹火箭筒,更不用说我们目前众多齐全的火炮品类,先进的隐身战机、强大的主战坦克,这些都是捍卫祖国的神兵利器。
七十年后,再次为伟大的中国人民志愿军感动,志愿军的精神,也必将永远鼓舞中国人民前进!
 (河口美景)
(河口美景)
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
| maniacata发表在《激动人心《我和我的祖国》》 | |
| 华发表在《姑苏行》 | |
| Francesca发表在《姑苏行》 | |
| George发表在《奥乌卡·莱蕾:狂乱的现实》 | |
| Yu发表在《清平乐·贺岁虎年》 |
